I wrote a blog post quite a while ago called gzip + poetry = awesome where I talked about how the gzip compression program uses the LZ77 algorithm to identify repetitions in a piece of text.
In case you don’t know what LZ77 is (I sure didn’t), here’s the video from that post that gives you an example of gzip identifying repetitions in a poem!
I thought this was a great demonstration, but it’s only half the story about how gzip works, and it’s taken me until now to write the rest of it down. So! Without further ado, let’s say we’re compressing this text:
1 2 3 | |
It’s identified apping and rapping as being repeated, so gzip then encodes
that as, roughly
1 2 3 | |
Once it’s gotten rid of the repetitions, the next step is to compress the individual characters. That is – if we have some text like
1
| |
there isn’t any repetition to eliminate, but a is the most common letter, so
we should compress it more than the other letters bcdefghijklmnop.
How gzip uses Huffman coding to represent individual characters
gzip compresses bytes, so to make an improvement we’re going to want to be able to represent some bytes using less than a byte (8 bits) of space. Our compressed text might look something like
1 2 | |
Those were totally made up 0s and 1s and do not mean anything. But, reading something like this, how can you know where the boundaries between characters are? Does 01 represent a character? 010? 0101? 01010?
This is where a really smart idea called Huffman coding comes in! The idea is that we represent our characters (like a, b, c, d, ….) with codes like
1 2 3 4 5 6 7 8 | |
If you look at these carefully, you’ll notice something special! It’s that none
of these codes is a prefix of any other code. So if we write down
010001001011 we can see that it’s 010 00 1001 011 or baec! There wasn’t
any ambiguity, because 0 and 01 and 0100 don’t mean anything.
You might ALSO notice that these are all less than 8 bits! That means we’re
doing COMPRESSION. This Huffman table will let us compress anything that only
has abcdefghs in it.
These Huffman tables are usually represented as trees. Here’s the Huffman tree for the table I wrote down above:
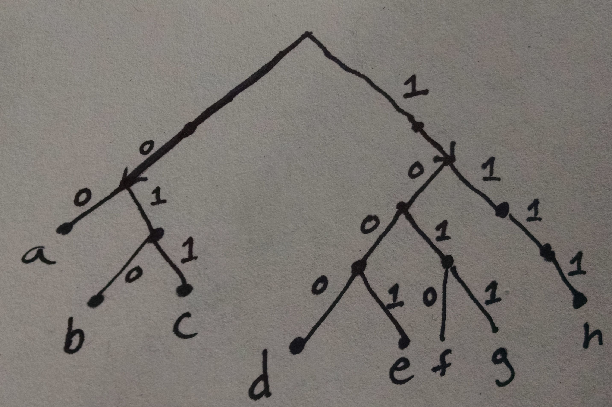
You can see that, for instance, if you follow the path 011 then you get to c.
Let’s read some real Huffman tables!
It’s all very well and good to have a theoretical idea of how this works, but I like looking at Real Stuff.
There’s a really great program called infgen that I found this morning that
helps you see the contents of a gzip file. You can get it with
1 2 | |
When we run./infgen raven.txt.gz, it prints out some somewhat cryptic output like
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
This is really neat! It’s telling us how gzip’s chosen to compress The Raven.
We’re going to ignore the parts that make sense (“Once upon a midnight
dreary..”) and just focus on the confusing litlen parts.
These litlen lines are weird! Thankfully I spent 5 straight days thinking
about gzip in October 2013
so I know what they mean. litlen 10 6 means “The ASCII character 10 is
represented with a code of length 6”. Which initially seems totally unhelpful!
Like, who cares if it’s represented with a code of length 6 if I DON’T KNOW
WHAT THAT CODE IS?!!
BUT! Let’s sort these by code length first, and translate the ASCII codes to characters.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
For starters, these are some of the most common letters in the English language, so it TOTALLY MAKES SENSE that these would be encoded most efficiently. Yay!
The gzip specification actually specifies an algorithm for translating these lengths into a Huffman table! We start with 000000, and then add 1 in binary each time. If the code length ever increases, then we shift left. (so 100 -> 1010). Let’s apply that to these code lengths!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
I found all this out by reading this incredibly detailed page, in case you want to know more.
I wrote a script to do this, and you can try it out yourself! It’s at https://github.com/jvns/gzip-huffman-tree
I tried it out on the compressed source code infgen.c.gz, and you can totally
see it’s source code and not a novel!
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
I really like going through explorations like this because they give me a better idea of how things like Huffman codes are used in real life! It’s kind of my favorite when things I learned about in math class show up in the programs I use every day. And now I feel like I have a better idea of when it would be appropriate to use a technique like this.