a boring xss dissection | discrete blogarithm
Hi there. Have a funny picture:
Today, I was briefly worried by the observation that mainstream media takes 24-36 hours to start freaking out about over half of web encryption being fundamentally broken, compared to 2-3 hours for an XSS bug in a Twitter client that causes self-retweeting tweets and unexpected rickrolls and such. Then I remembered that most Americans watch TV for like 4+ hours per day. (XSS is arguably the most telegenic class of software QA issues.)
I don’t use TweetDeck, but I managed to download the much-XSSed Chrome extension today shortly before it was fixed. I unminified the content script (the one that modifies page content on the client side, therefore probably causing whatever XSS was there) and took a diff with the patched version (3.7.2) after it came out. Pastebin here.
A couple things stood out:
- Some people on Twitter (or maybe the people who XSSed their accounts, haha) implied that the XSS was due to Twitter not escaping user input. This seems false, because I can see safely-escaped HTML in HTTP responses from Twitter in my browser. This is sort of interesting, because it implies that the TweetDeck client is somehow unescaping escaped HTML.
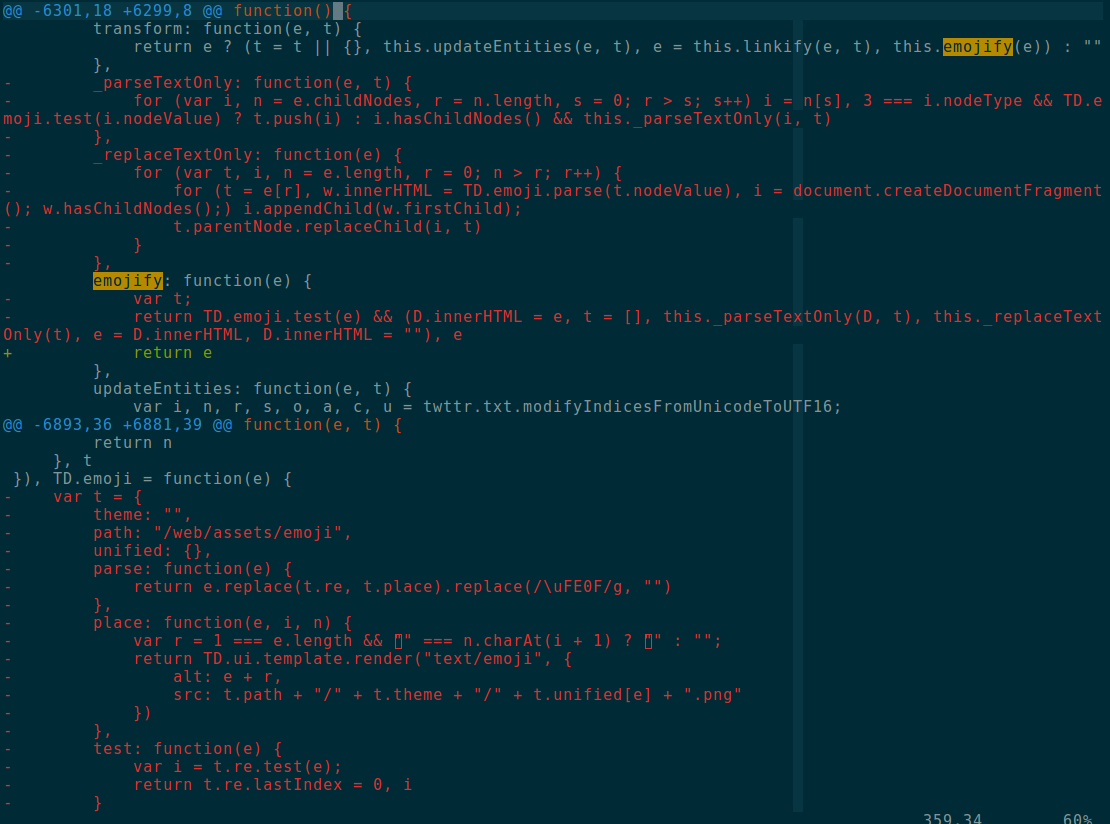
- The bulk of the not-very-well-obfuscated-but-still-hard-to-read diff between 3.7.1 and 3.7.2 was ripping out emoji “parsing” code. “parsing” is in quotes because TweetDeck processes tweets and tries to replace all Emoji characters with HTML image tags before showing them to you.
3.7.2, quite happily, replaced the “emojify” function with the identity function (pictured above).
After staring at the diff some more, I sort-of figured out what was going on. TweetDeck runs a utility function on the DOM that extracts every text node, t, that contains an emoji character. Then for each text node t, it does the equivalent of:
someDiv.innerHTML = this.emoji.parse(t.nodeValue);
var i = document.createDocumentFragment();
while (someDiv.hasChildNodes()) {
i.appendChild(someDiv.firstChild);
}
t.parentNode.replaceChild(i, t);where emoji.parse is the function that replaces emoji with HTML img tags.
“innerHTML is evil!!” one might say. This is true, but not the sole problem in this case because Chrome and Firefox will not automatically execute js inside <script> tags created by setting innerHTML. While it’s true that you can get scripts to execute anyway through <img onError=”…”> or whatever, there were consistent reports today of people who got XSSed through <script> tags in tweets.
So given that it’s not 120% obvious where the bug is in the TweetDeck code, here’s what happens when you try out the code snippet above on a tweet containing both XSS payload and emoji, like this one:
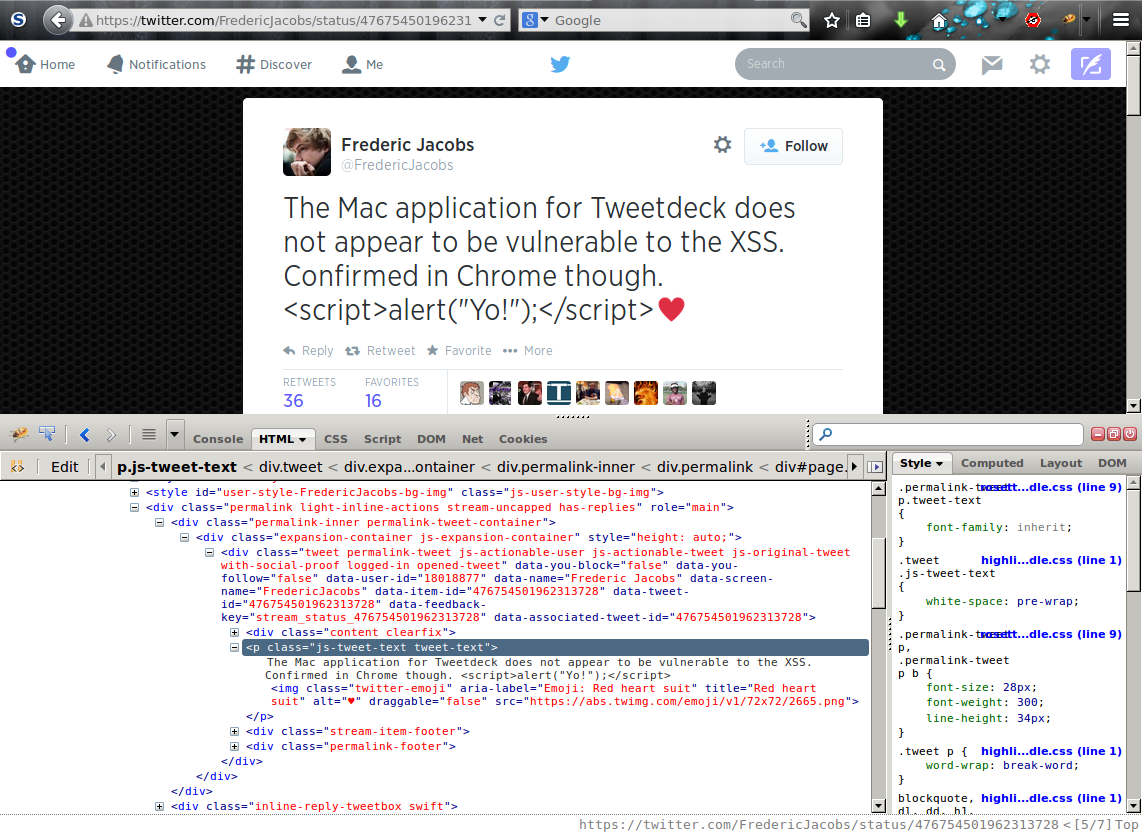
For convenience, I ID’ed the element containing the tweet text with “xss-test”. Looks like the innerHTML is properly escaped to start with!
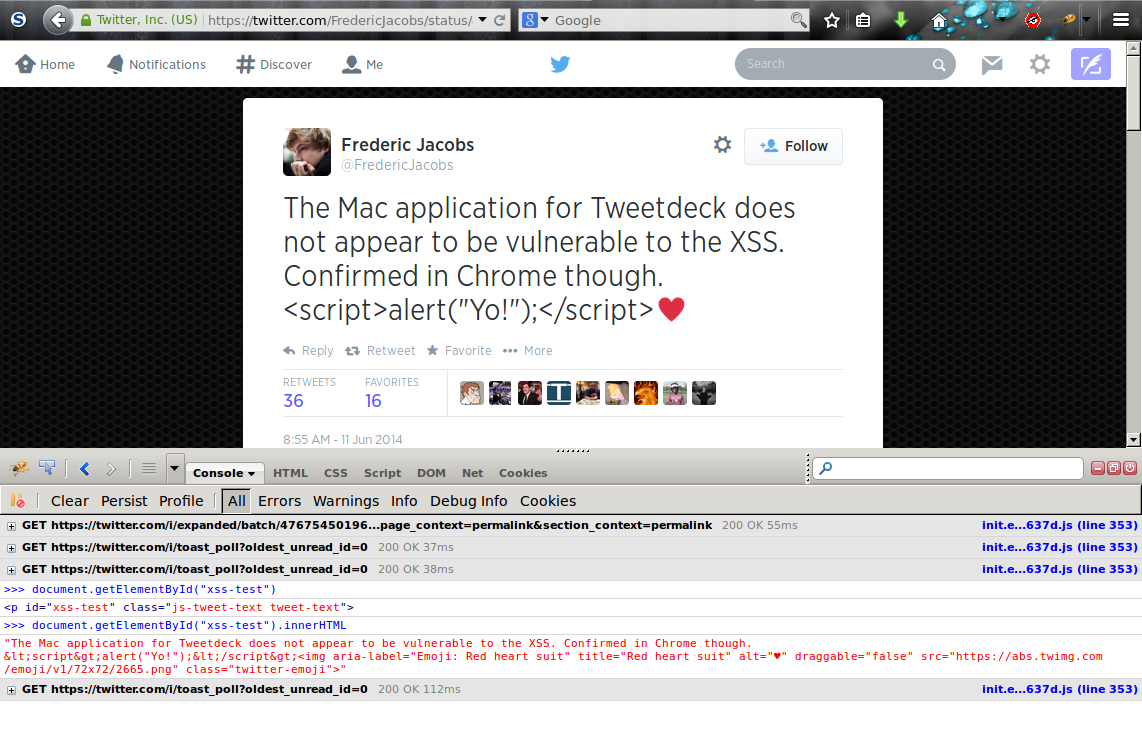
Now let’s grab the text node corresponding to the tweet, create a new div, and set the innerHTML of the div to be the nodeValue of our text node (TweetDeck would have converted emoji into images at this point, but this was already done to start with). Note that the new innerHTML doesn’t seem to have safe HTML entity-encoded characters (<, >) anymore!
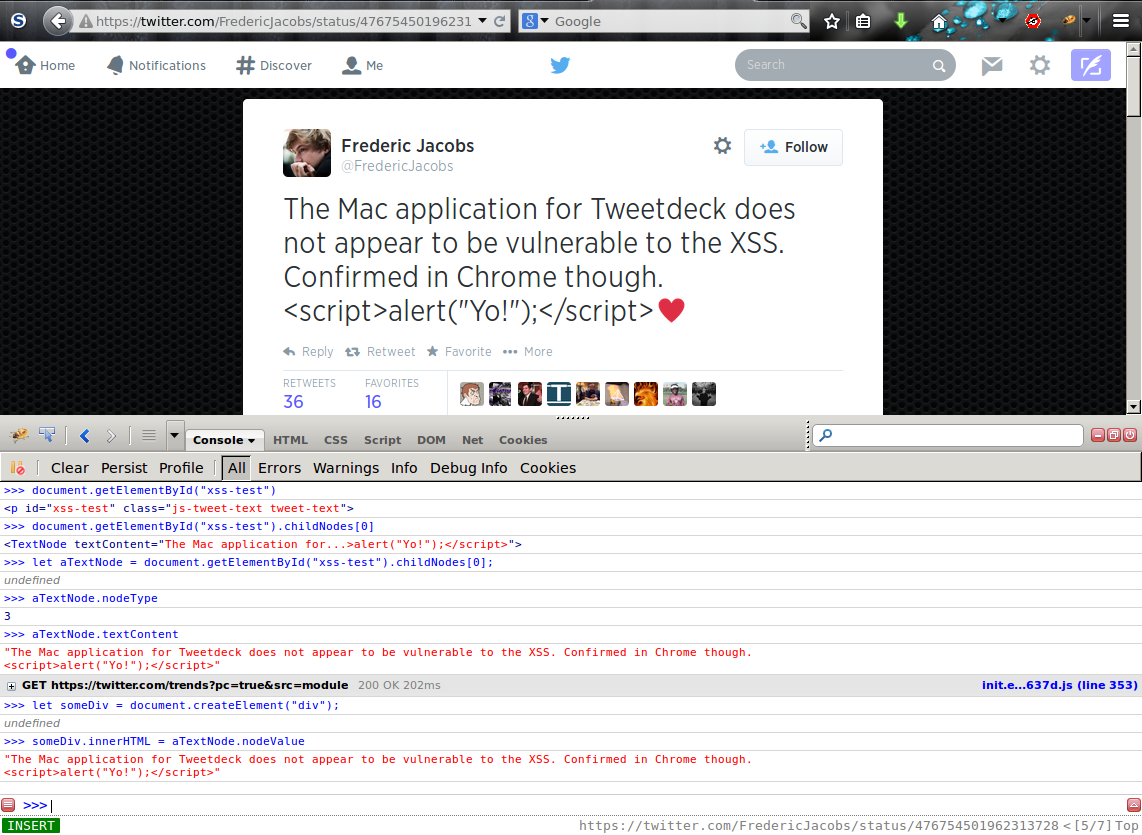
Moving on, we create a documentFragment and append *both* children of the new div to it. Note that the second child is a script element, which wasn’t originally part of the DOM! Finally, we do some DOM surgery to replace the original text node with our newly-created fragment.
And voila, the <script>…</script> text in the tweet disappears, because now the browser sees it as a script element instead of as text.
It’s not hard to imagine ways this bug could have been created. UX designer says, “We need to add better emoji rendering before the release next week.” Another developer decides that emoji need to be converted into images and copies-and-modifies some code from the same script that renders “@” mentions in text as HTML links but forgets to re-sanitize the non-emoji text. The code looks pretty okay, with no obvious problems, so it gets pushed out.
This is the sort of thing that I suspect is *all over* every semi-clever agilely-developed app, waiting to be uncovered as soon as a mischievious Austrian teenager accidentally hits the wrong key. Most applications simply don’t have enough users for these bugs to surface yet, and many will die out before they ever do, which is a blessing in itself. Sometimes the bugs are found and fixed before they explode all over Ars Technica, either by a scrutinous engineer or by an honest user or perhaps by someone looking to claim a bug bounty.
But these generally aren’t bugs that can be trivially prevented, unless the developer who’s working on improving emoji rendering for your project also happens to have enough of a security background to know that changing some safe innerHTML to the nodeValue of the safe innerHTML will suddenly create dangerous innerHTML. Or perhaps if you had a dedicated person reviewing each commit for security holes as it comes in, or at least a pre-release hook for automated fuzz testing to check for unwanted script execution, but last I checked, nobody was telling web application devs to do this.
My favorite solution is actually for everyone to just deal with being XSSed semi-frequently in the future. This means that developers should stop exposing sensitive tokens to javascript (or quickly expire tokens that are), use safe CSP directives whenever possible, and make it easy for users to review and undo actions. On the other side of the bargain, users should either start using NoScript-like browser settings to whitelist Javascript or at least blacklist known Rickroll links.