What Makes a Website "High Performance"?
What is performance?
Creating a high performance web site is a delicate dance. Many people think it’s just about how fast your JavaScript performs. The reality is that it’s far more than that. There are also multiple ways to measure performance.
The first is load time. From the time that a user clicks a link or enters a URL into the address bar, how long does it take to load that page? Even this has multiple definitions as there’s one hand where it’s how long it takes to completely load the page and on the other hand it’s the user’s perception of how long before the page does something useful or is responsive.
For example, you could load the main content and make the page available for interaction while you programmatically go back to the server and grab the rest of the content.
The second performance metric is more complicated. This one is about how fast animations and interactions on your site perform in the browser.
Web Runtime Architecture
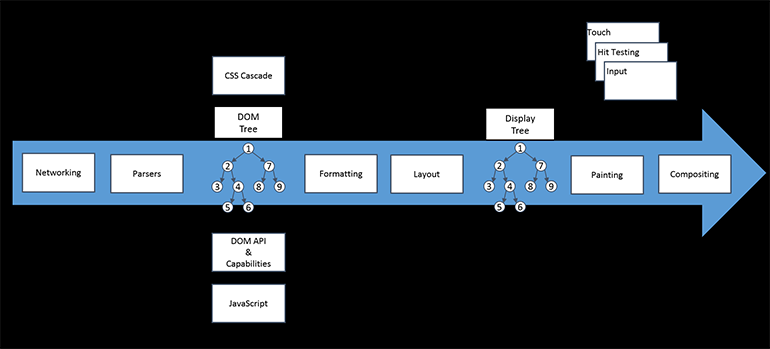
In both cases, it takes a great understanding of the web runtime architecture to tune either of these cases. I’m deliberately saying web runtime architecture rather than the IE runtime architecture because all of the browsers have roughly the same architecture when talking about it at this level because they are all implementing the same standards. They may have different names for their subsystems or have optimized one over the other but in general this is the flow of every browser.
Roughly, there are three categories of things to think about, those that affect network, those that affect the CPU and those that affect the GPU.
Network
The first thing that happens is networking. Networking starts when the URL is first entered. For now, I’ll be talking about starting with an HTML page but the reality is that networking handles whatever type of resource that’s referenced by the page including XML, JSON, IMG, PDF, etc. and different subsystems come into play for various resources.
But let’s start with an HTML file. Firstly, the browser begins downloading the HTML file and as it’s downloaded, pre-processing begins. Pre-processing looks into the file for anything else that the HTML references that the browser could start downloading. This includes CSS files, JavaScript files, images or whatever is referenced by the file.
This is important because the browser needs to have all of the referenced content at hand as quickly as possible because it’s all interdependent; the HTML relies on the CSS and the JavaScript, the JavaScript can only talk to the DOM which is built from the HTML and the CSS doesn’t have anything to style without the HTML DOM which the JavaScript can manipulate. Yes, that’s a bit confusing but hopefully it will make more sense here shortly.
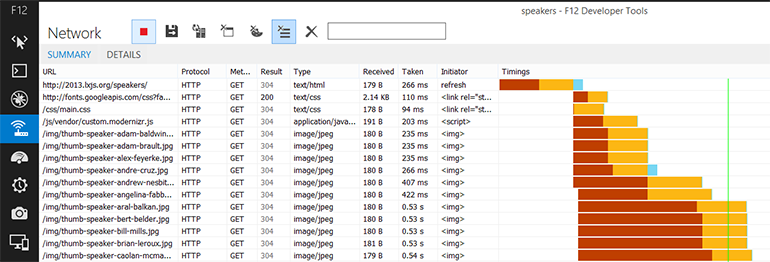
An important issue to consider is that, per the spec, browsers are only allowed to open six simultaneous connections to any given server and a connection is needed for each resource specified in the HTML. That doesn’t sound like a lot of connections when you look at pages that have a lot of image content, JavaScript files, CSS files such as Facebook, Pinterest or the like. In fact, it sounds quite crippling.
It’s actually up from where the spec started which was two simultaneous connections! The reason for this limitation is to help a server detect a Denial of Service Attack (DOS or DDOS), where the client opens up as many connections as possible and takes as much of the bandwidth from the server as they possibly can. The good news about the six limit is that it allows the browser to go get more content at the same time.
The vast majority of web sites that I see have all of the content coming from the same site. Best practice where there’s a number of images, CSS, JavaScript or other assets is to split those resources across different domains. This is one of the quick wins for using a CDN (Content Delivery Network). This also why it makes sense to use a hosted version of common JavaScript frameworks rather than putting it on your own server.
Parsers
Once an item is downloaded, it goes to the parsers. There are dozens of parses that parse everything including — but not limited to — HTML, CSS, XML, XHTML, SVG, JavaScript and variations on all of these. The job of the parsers is to create the internal data structures that the browser will be using for the rest of the processing.
I’m over-simplifying the job of the parsers, and just covering those could be an entire separate article. The important part about the conversation at the moment is that writing well-formed documents — HTML, XML, XSLT, JSON… — can improve your load time.
Internal Data Structures
There are a number of different internal data structures that the browser needs to accomplish its tasks. The best known of these is the DOM (Document Object Model). If you’ve done any JavaScript programming on a web site before, you’ve probably interacted with the DOM at some level. The general thought is that the DOM is slow and painful. The reality is something more complicated.
Every time something touches the DOM, it affects everything downstream from there. Why that’s a problem will become clearer in just a bit.
Another very important structure to understand is the CSS Cascade. This is an amalgamation of all of the CSS rules that are referenced in the HTML and all of the CSS files as well as the rules that are set programmatically by JavaScript. It incorporates all of the orders of precedence as to what overrides what and so on.
JavaScript
The JavaScript sandbox is where JavaScript parsing, byte code generation, native code generation and all of the execution of JavaScript happens. This is why JavaScript is safe to run inside of browsers. It’s not that it’s a safe language. Quite the contrary, it’s an incredibly powerful language that if unchecked could run rampant over everything on your machine.
Rather, it’s safe because JavaScript only has two ways out of the sandbox – to call the DOM API or to call the network via XHR requests. There are a ton of frameworks that help with both of these tasks – jQuery is one of the most popular. The $(“path statement”) syntax is incredibly powerful as a selector for the DOM. The $.getJSON() method is an incredibly simple to use and fast method of making AJAX requests.
Styling – Formatting and Layout
The next step, styling, actually covers two subsystems.
The first styling subsystem is formatting. Formatting is important because the DOM tree is completely ignorant to anything visual. All it knows is the parent child relationships between the elements and the attributes. It’s the CSS cascade that knows all of that information. During formatting this information is joined up giving the DOM elements size, color, backgrounds, font sizes and so on.
At the end of this subsystem, the individual elements each know what they look like.
The next step, now that all of the DOM elements know what they look like, is to figure out how they look together on the page – this is the layout process.
CSS is inherently a block based layout. This means that everything; images, paragraphs, divs, spans, event shapes such as circles, are actually blocks to CSS. The big question is how big of a block. And HTML/CSS is inherently a flow based layout unless something overrides that. This means that the content, by default, will go to the next available top right-hand corner in which it fits.
So if your screen is 800px wide, and you have four elements that are 300px wide each, you’ll fit two across the top and the third one will go on the next row of items. The CSS Cascade can override this however and position items either in a relational or absolute manner. If it’s relational, its position is dictated to be a certain distance from the previous item that was laid out on the screen.
If it’s absolute, it ignores all of the rules and is laid out a certain distance from the uppermost right hand corner of the page. In this case, it’s likely that it will even be positioned over another item on the screen.
As such, the primary job of the layout engine is to put all of the blocks on the screen. This includes positioning objects based on their relative or absolute positioning, wrapping or scaling things that are too wide and all of the other things that go into that lightning round of Tetris that is required.
At the end of the layout phase, the browser has an internal structure called the display tree. This is an interesting data structure. Some folks ask why browsers don’t just use the DOM tree but it’s not a 1-1 relationship between the items in the DOM tree and the items in the display tree. While this may take a moment to get your head around, it makes sense.
There are things that are in the DOM tree that are not in the display tree such as elements that are display:none or input fields that are type=hidden. There are also things that are in the display tree that are not in the DOM tree such as the numbers on an ordered list ( <ol><li>asdf</li></ol> ).
Paint and Compositing
At this point, the styling is done and the display tree is ready to paint. There’s a careful choice of words there in that the browser is ready to paint but is not painting just yet. What’s next requires the hardware to tell the browser the next time to do a paint to the screen. Monitors can only paint so many times a second. Most modern day ones do that 60 times a second, thus the 60 hertz refresh rate.
This means that it’s 1000/60 (milliseconds divided by the refresh rate) on most monitors between refreshes which works out to 16.67 milliseconds (roughly). That doesn’t sound like a lot of time but in reality a modern day I7 processor can run roughly 2138333333 instructions (Millions of instructions per second as noted in Wikipedia on Instructions per Second/60). Between me and you, that’s a lot of instructions.
It’s not infinite but it’s a lot. It means that the computer can do roughly 35638889 instructions between monitor refreshes.
When the monitor is ready to paint, it sends the hardware interrupt which initiates the paint cycle. At this point, the browser paints the layers of the page to the surface which for IE is DirectX surfaces which are composited and displayed on the monitor for your user’s enjoyment by the Desktop Windows Manager (DWM).
Interaction
At this point, the browser has shown something on the screen so this is load time. However, there is no animation yet or any interaction.

Interaction includes things such as mouse, pointer or keyboard events. All of these touch the page in some form or fashion. When a user touches the screen somehow, the browser will have to look at the formatting and layout to see what was touched. Then it has to look through the DOM to see if there was a corresponding event that needed to be fired when that item was touched. If an event is found, then JavaScript can kick off and execute the event code, touching the DOM tree.
Hopefully at this point you can see the issue there. Touching the DOM tree means that the display tree is no longer an accurate representation of the DOM. This means that the browser needs to redo the layout and the formatting and get ready to re-paint.
This is what I meant earlier when I said that describing the DOM as being “slow” is complicated. It’s not that manipulating the DOM is particularly slow by itself. What’s slow is that touching it creates the domino effect of forcing the other subsystems to trigger.
Recap of the Web Runtime Architecture
Hopefully this gives you a picture of the entire web runtime architecture. There’s not one specific component that drives performance of your site. It’s a myriad of things and in fact, sometimes focusing on one thing will cause another to suffer. For example, if you combine all of your JavaScript files into one, that’s only one file that needs to be downloaded but it also means your page is potentially blocked until that entire JavaScript file has been downloaded and parsed.
Understanding what to do to get the best performance reduce the impact of those decisions is what makes the difference between a good and a truly great web developer.