火车警示录
火车警示录是为了警告那些可能因城市有多个火车站而去错始发站的人们。其制作灵感来源于我经历的真实故事。
去错始发站的故事
2013.08.21我提前近一个小时来到北京西站,轻轻松松地,慢慢悠悠地来到验票口,等到验票员告诉我车票上是从「北京站」上车的车次时,我愣了,此时离发车还有40分钟,好几个人凑上来「抢」我(后来我才意识到这些人都是做摩的生意的),最终,我坐上一辆摩的到了北京站,也无奈地被宰了150元。登上火车后,我在qq里这样写到:
当年我在北京西站进站时,遇到一个工作人员给一个大妈说:你这是北京站的票……当时是过年前夕,我内心无比同情。此后,我跟很多同学讲:北京不知道给大妈大叔及农民工们在买票时就提醒不要误以为成另一个“北京”站的做法糟糕透了,这么关键的地方都不为弱势人员着想。结果今天我撞上了,最后花了150¥坐摩的从北京西站赶到北京站,也第一次知道西站到北京站的摩的已经成为一个产业,路上飞奔北京站的摩的不在少数。如果我今天用的是一款竞争环境下的产品,它便永远也没有被我用的机会了,可是它是12306,今生誓与垄断为敌。
在我这篇博客里主要展示火车警示录和其制作过程,不打算谈论铁道部垄断的坏处。
我那天的车次是K267,要去的城市是襄阳,我们看看北京到襄阳的车次: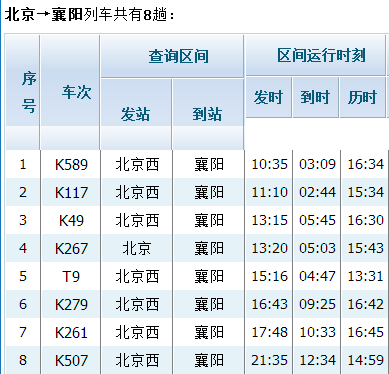
一共有8次列车,其中7次是从北京西站发车,只有K267从北京站发车。我以往认为,往南方的车,尤其是接近直线从北往南的车基本都是从北京西站发车的。所以在网上刷到那张K267时没有注意始发站,取票时也没有注意,最后的结果带着无比复杂的心情坐在摩的上抢车道,闯红灯,上演生死时速。
让我们看看北京四大火车站在北京市地图上的大致位置,发现四大火车站差不多组成一个菱形,相邻距离都不算近,若不考虑车站附近较堵的情况,坐快的公交车和出租车差不多都能在30分钟内从相邻车站赶到,但是要知道在北京的火车站能快速坐上公交或的士也是一件很有挑战的事。
#画出北京的四个车站在北京市地图上的位置 library(ggmap) map <- get_map(location = 'Beijing', zoom = 12, maptype="terrain") bj.stations <- geocode(c("beijinghuochezhan","beijingxizhan","beijingnanzhan","beijingbeizhan")) bj.names <- c("北京站","北京西站","北京南站","北京北站") ggmap(map)+geom_point(aes(x=lon, y=lat), data=bj.stations)+geom_text(aes(x=lon, y=lat, label=bj.names), data=bj.stations, size=10, colour = "red")

火车警示录的构想
从去错车站的故事后到现在,我又坐了一次火车,在北京西站北广场稍一留意,就发现一个正在焦急打电话对另一头的人说去错车站了。验票进展时,前面的两个人正巧上演了我8月份的悲剧。再想想好多年前回家过年却走错站的大妈,想想8月事件中我身边的其他摩的,这真的不是什么个例,真不能只怨我们自己。在12306网站做到售票时提醒用户和铁路公司制定更合理的线路之前,我有特别强烈的做一个火车警示录的欲望。当前的构想也比较简单,就是:找到所有的从北京去往别的城市容易出现去错始车站的「危险」车站,比如襄阳站;找到从北京出发的所有「鹤立鸡群」的车次;再以比较好的数据可视化的方法让看到火车警示录的人印象深刻,尤其是自己的家乡车站也是「危险」车站的朋友。
火车警示录的创建流程
获取原始数据
我首先在12306网站上,查询了所有从北京始发的火车车次,共389次。不同日期,车次数量差别还蛮大,例如下面这张图查询的是2013.10.1的,多达423次,可能因为节日增加车次了。
然后,我用scrapy爬虫框架从酷讯网上去爬取每一个车次的所经过的车站信息(即路线),共爬取到380个车次的信息。由于列车经常变动,从酷讯查不到另外9个车次的信息也是可以理解的。所爬取的信息保存为json文件,形式如下:
[{"route": ["北京", "北戴河", "秦皇岛"], "checi": "Y509"}, {"route": ["北京", "保定", "石家庄", "邢台", "邯郸", "安阳", "新乡", "郑州", "许昌", "漯河", "信阳", "武昌", "咸宁", "岳阳", "长沙", "株洲", "醴陵", "萍乡", "宜春", "新余", "樟树", "丰城", "南昌"], "checi": "T145"}, {"route": ["北京", "天津西", "沧州", "德州", "徐州", "南京", "镇江", "常州", "无锡", "苏州", "上海"], "checi": "T109"}, {"route": ["北京", "唐山北", "滦县", "北戴河", "秦皇岛"], "checi": "T5687"}, {"route": ["北京", "宣化", "张家口南", "集宁南", "呼和浩特东", "包头", "临河", "乌海", "石嘴山", "银川", "中卫", "武威", "金昌", "张掖", "嘉峪关", "柳园", "哈密南", "鄯善", "吐鲁番", "乌鲁木齐"], "checi": "T177"}, {"route": ["北京西", "郑州", "武昌", "长沙", "广州东"], "checi": "T97"}, {"route": ["北京西", "郑州", "武昌", "长沙", "广州东"], "checi": "T97"}, ...(此处省略其他车次信息) ]
使用R语言和Excel处理数据和分析
将json文件读到R里,用R语言进行数据变换和分析等操作。
require(rjson) #trains是list对象 trains <- fromJSON(file="D:/百度云/resources/火车警示录/beijing_train.json") start.station <- read.table(file("D:/百度云/resources/火车警示录/start_station.txt", encoding="UTF-8"), header=TRUE, sep="\t") #将list对象转换为dataframe;route,checi -> c(station, checi) df.trains <- data.frame() for (train in trains) { temp <- cbind(train$route, train$checi) df.trains <- rbind(df.trains, temp) } names(df.trains)[1] <- "station" names(df.trains)[2] <- "checi" huoche <- merge(df.trains, start.station, by="checi")
数据框对象huoche的形式如下:
> head(huoche) # checi station start_station #1 1303 北京西 北京西 #2 1303 任丘 北京西 #3 1303 深州 北京西 #4 1303 衡水 北京西 #5 1303 清河城 北京西 #6 1303 聊城 北京西
#获取车站和始发站关联的二维矩阵,矩阵元素为从始发站Y发往车站X的车次数目 start.number <- table(huoche$station, huoche$start_station) #summ.star.num <- summary(start.number[,1:dim(start.number)[2]])
矩阵start.number的形式如下。还可以看出北京往全国768个车站都有直达车次。
> start.number[1:6,] # # 北京 北京北 北京南 北京西 # 北戴河 20 0 0 0 # 北京 83 0 0 0 # 秦皇岛 20 0 0 0 # 安阳 3 0 0 16 # 保定 4 0 0 28 # 丰城 1 0 0 0 > dim(start.number) [1] 772 4
为了识别一个车站有多「危险」(即去错始发站),我定义了一个危险度公式:始发站到车站S车次数目的最大值 / 始发站到车站S的车次数目的均值。以保定站为例,危险度就是:28/((4+0+0+28)/4) = 3.5。而像北戴河站,只会从北京站发车,完全没有危险,但是算出来的危险度为4,所以还要重置为0.
#ratio为所有车站的危险度向量,越大越危险 ratio <- apply(start.number, 1, FUN=function(x){return(max(x)/mean(x))}) ratio[ratio==4] <- 0 ratio <- sort(ratio, decreasing=T)
> ratio[1:6] # 石家庄 阳泉北 高碑店 天津 定州 石家庄北 #3.822222 3.764706 3.692308 3.644444 3.636364 3.600000
到此主要的数据都已经得到了,接下来就是寻找合适的数据可视化方法了。
我先用Excel把危险车站的关键数据直接展现出来,如下:
大家可以看看排在前几名的车站,各个都是危险至极,去往石家庄站的车从北京西发车的多达86次,去石家庄的朋友会不会感叹原来还有从北京站发石家庄的车次呢?
通过观察还发现:除了「怀柔」「通州西」「兴隆县」三站,危险全部是由「北京站」造成的,危险车站的「鹤立鸡群」的车次都是从北京站出发的。
显然上面的数据信息表很难让人耐心地找找上面有没有自己的家乡车站。所以我在地图上把这些车站都给标记出来,希望大家能一眼看到自己的家乡车站有没有出现在地图上。
在地图上标记危险车站
为了能在地图上标记车站,我需要使用ggmap包来获取各个车站的经纬度,前提是我先要将车站的中文名字给全部翻译成不带声母的汉语拼音,存于station_name.txt文件。由于地方太小,或者名字有歧义,使用拼音通过ggmap获取的经纬度会有少失准情况,或者无法获取。需要人工对这样的车站使用更详细的拼音名字,比如把「beijingzhan」改为「beijinghuochezhan」,把「anyang」改为「anyang of Henan」。
station.name <- read.table(file("D:/百度云/resources/火车警示录/station_name.txt", encoding="UTF-8"), header=TRUE, sep="\t") #通过google map API获取各个车站的经纬度 for (name in station.name$name) { temp <- geocode(as.character(name)) station.name$jd[station.name$name == name] <- temp$lon station.name$wd[station.name$name == name] <- temp$lat } #将车站的风险值添加到station.name中 for (station in station.name$station) { station.name$risk[station.name$station == station] <- ratio[station] } #将记录按照车站危险度降序排列 station.name <- station.name[order(-station.name$risk),]
此时,数据框对象station.name的形式如下:
> head(station.name) # station name jd wd risk #12 石家庄 shijiazhuang 114.5149 38.04231 3.822222 #97 阳泉北 yangquanbei 113.4420 38.11568 3.764706 #337 高碑店 gaobeidian 115.8738 39.32652 3.692308 #65 天津 tianjin 117.2010 39.08416 3.644444 #336 定州 dingzhou 114.9903 38.51617 3.636364 #94 石家庄北 shijiazhuangbei 114.4658 38.06679 3.600000
现在,我们在全国地图上标记 risk>=3.0的车站,risk>=3.5的车站用大号字体标记。
#输出全国badstations位置图像 svg("mark-qg-all.svg", family="GB1") source("mark_quanguo.R", encoding="utf-8") #mark_quanguo.R脚本代码附注在了后面 dev.off()
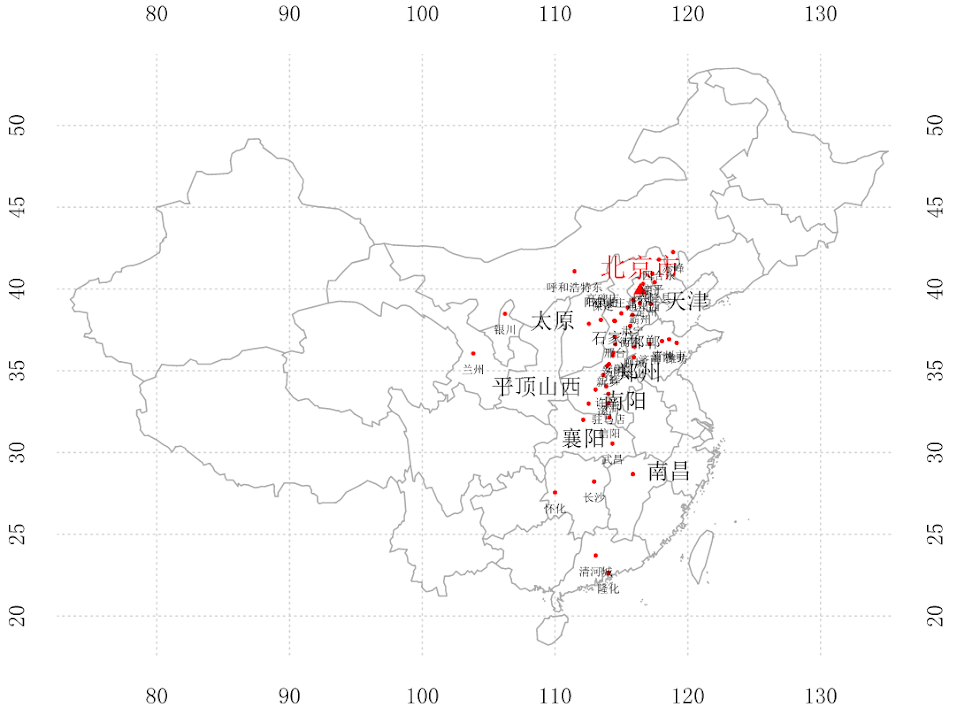
我们可以看到,离北京的距离很远的危险车站并不多,若有你家乡车站一定要当心哦。但在整个华北地区,危险车站云集,根本无法看清。我们只好再专门观察一下华北地区的危险车站,红圈大小表示了车站的危险程度。

考虑到我的家乡襄阳站的危险度为3.5,并且我已经踩过地雷,所以我认为比襄阳站危险度持平或更高的车站有必要单独标记在地图上,警示他人。全国地图和华北地图上的risk>=3.5的车站分布分别如图

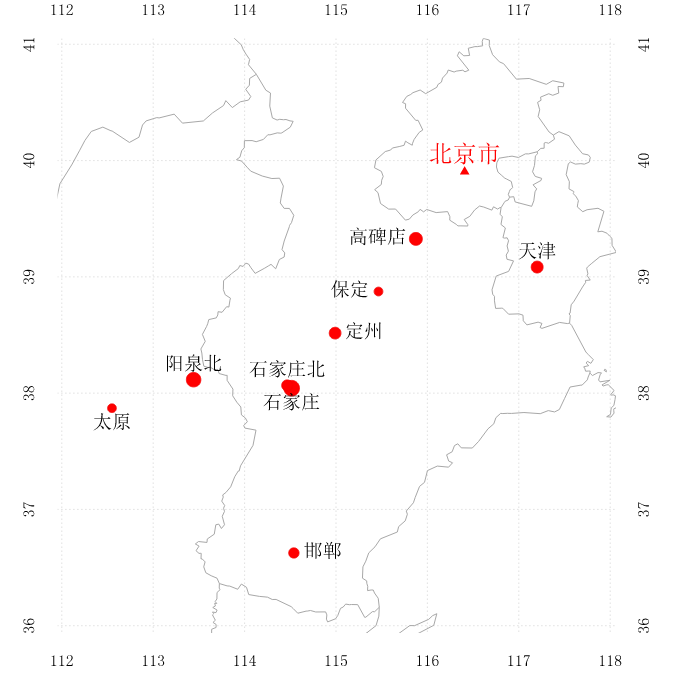
展示最危险的车次
到目前为止,我都是想让大家加深危险车站的印象,而实际上与出现走错车站问题最直接相关的是去往那些危险车站的危险车次。然而,大家的目的车站会各不相同,且在出问题之前,我们可能无法记住我们还没坐过的危险车次。所以列举出所有的危险车次可能没有意义。好在很多危险的车站中都有着共同的危险车次,我将经过超过2个危险车站的危险车次展示出来:
#显示北京到这些雷区车站的车次信息 special <- ratio[ratio>=3.5] badhuoche <- huoche[huoche$station %in% names(special),] badhuoche <- badhuoche[order(badhuoche$station),] badhuoche <- badhuoche[badhuoche$start_station == "北京",] #剩下的使用Excel的数据透视表处理
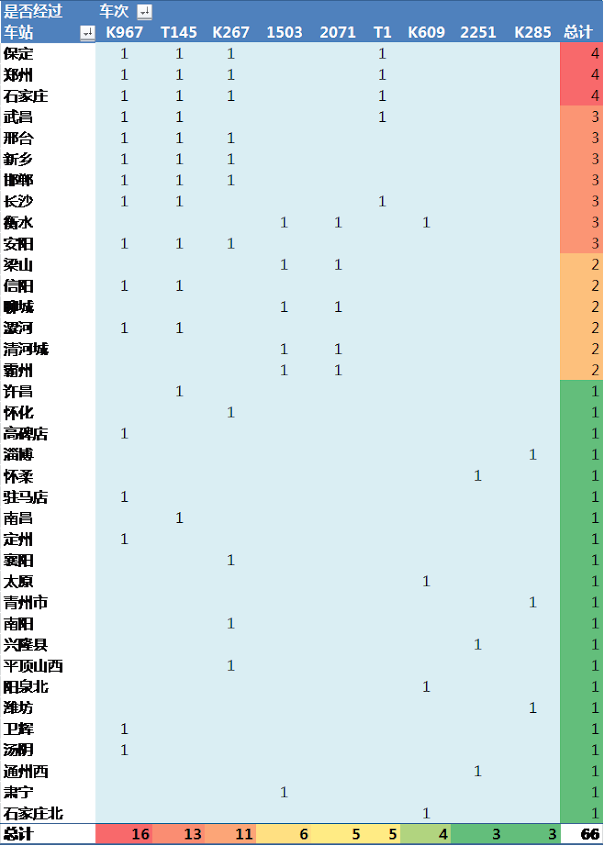
从上图可以看到,邪恶的K267还并非是邪恶之王,K967次列车一共经过了16个危险车站,就是说去往这16个城市车站的人都有可能被K967坑。再认真地看看一下这几大车次和他们经过的车站吧。
结语
好了,到这里,火车警示录咱告一段落了。数据透视表并非展示这种数据特别的好的方式,使用circos也许能作出更好的可视化效果,等以后学会了再补充进来吧。在此片文章中代码比较详尽,但省去了文本处理的一些工作展示。有兴趣的朋友可以把始发站换成「上海」或「广州」,用这些代码跑一遍,看看这些城市是什么情况。
如要转载,请保留原作者及链接信息。源地址http://zisong.me/post/zuo-pin/huo-che-jing-shi-lu
附注:在地图上标记车站的脚本代码
#mark_quanguo.R library(maps) library(mapdata) par(mar=rep(0,4)) temp <- station.name[station.name$risk >=3.0,] dat = temp[,c("station","jd","wd","risk")] map("china", col = "darkgray", xlim=c(73,135), ylim=c(18,54), panel.first = grid()) #把北京市单独标记出来 points(116.4075, 39.90403, pch = 17, col = "red") text(116.4075, 39.90403, "北京市", cex = 1.2, col = "red", pos=3) #把危险车站标记出来 points(dat$jd, dat$wd, pch = 19, cex=rep(0.3, nrow(dat)), col = "red") text.cex <- c(0.7,0.5,0.5,1,0.5,0.5,0.7,1,1,0.5,1,1,1,1, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5) text.pos <- c(1,3,2,4,4,3,4,4,4,2,2,1,4,2,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1) text(dat$jd, dat$wd, dat[, 1], cex = text.cex, col = "black", pos = text.pos) axis(1, lwd = 0); axis(2, lwd = 0); axis(3, lwd = 0); axis(4, lwd = 0)
#mark_huabei.R library(maps) library(mapdata) par(mar=rep(0,4)) temp <- station.name[station.name$risk >=3.0,] dat = temp[,c("station","jd","wd","risk")] map("china", col = "darkgray", xlim=c(110,120), ylim=c(32,42), panel.first = grid()) #把北京市单独标记出来 points(116.4075, 39.90403, pch = 17, col = "red") text(116.4075, 39.90403, "北京市", cex = 1.2, col = "red", pos=3) #把危险车站标记出来 points.size <- (dat$risk - 3.4)*3 + 1.5 text.cex <- c(1,1,1,1,1,1,1,1,1,1,1,1,1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1) text.pos <- c(1,3,2,4,4,3,4,4,4,2,2,1,4,2,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1) points(dat$jd, dat$wd, pch = 19, cex=points.size, col = "red") text(dat$jd, dat$wd, dat[, 1], cex = text.cex, col = "black", pos = text.pos) #1,3,2,3,4,3,4,4,4,2,1,1,4,2 axis(1, lwd = 0); axis(2, lwd = 0); axis(3, lwd = 0); axis(4, lwd = 0)